~「精度90%の壁」というAI OCRの課題を解決。データ入力作業人員を80%以上削減可能に~

Irwin&co株式会社(本社:東京都渋谷区円山町5丁目5号、代表取締役:アーウィン海)は、「AI OCRを導入したが精度に満足できない」「これからデータ入力の自動化を検討している」という企業様に向け、生成AIを活用した「PDF構造化技術」により、高精度にPDFデータを読み取る法人向けソリューション(以下、本システム)を正式リリースいたしました。本技術は、不動産マイソク(販売図面)、登記簿謄本、帳票等のPDF、PowerPoint・Excel等からエクスポートされたPDFが混在する非定型フォーマットにおいて、99.9%のデータ読み取り精度を実現します。従来のAI OCRでは避けられなかった「目視チェックと手修正」の手間を解消し、データ入力業務の真の自動化を実現します。
■ 開発の背景 - 「AI OCR導入後も残る、人手による修正コストと精度の壁」
近年、多くの企業がデータ入力業務の効率化を目的に「AI OCR(光学文字認識)」を導入しています。しかし、導入企業からは「期待したほど楽にならない」という声が多く聞かれます。その原因は、従来のOCR技術が抱える構造的な課題にあります。
認識精度の限界(90%の壁):PDFを単なる「画像」として処理するため、読み取り精度は高くても90%程度にとどまります。
残る手作業:残りの10%の誤読を修正するために、結局は人間が全件を目視確認する必要があり、コスト削減効果が限定的です。
形式が不揃い:表組みや段組が複雑な書類では、「どの数値がどの項目か」を文脈から理解できず、正しくデータ化できません。
Irwin&coは、これらの課題を抱える企業様、そしてこれから失敗のないシステム導入を目指す企業様のために、AI OCRとは根本的に異なるアプローチで本システムを開発しました。
■ 解決策 - AI OCRとは根本的に異なる「PDF構造化技術」
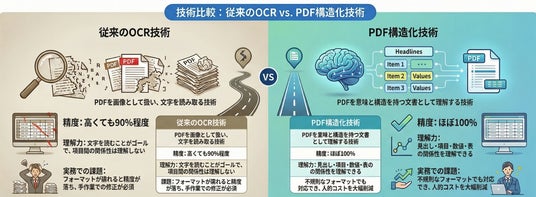
従来のOCRがPDFを「画像(絵)」として読み取っていたのに対し、本技術はPDFを「意味と構造を持つ文書」として認識します。
テキストデータを含むPDFに対しては、テキスト情報を直接抽出し構造化することで約100%の精度を実現。スキャンデータ等の画像PDFに対してのみ画像解析を行うハイブリッドな処理により、全体として99.9%という圧倒的な読み取り精度を達成しました。
[表: https://prtimes.jp/data/corp/167715/table/7_1_c50cfe15266e3815d2f1d9a2758d2140.jpg?v=202601070245 ]
■ 本システムの特徴
(1)AI OCRの限界を超えた「意味理解」による高精度読み取り
生成AIが「見出しと数値の関係」や「表の構造」を文脈から理解します。単に文字を拾うだけでなく、「この数値は何の項目か」を推論できるため、人間と同等以上の精度でデータベース化が可能です。
(2)あらゆる不規則フォーマットに対応
不動産会社ごとにレイアウトが異なる「マイソク(販売図面)」や、形式がバラバラな「PowerPoint」「Excel」「登記簿謄本」などが混在した状態でも、AIが自動でファイル形式と内容を判別し、正確に情報を抽出します。
(3)入力コストを大幅圧縮
精度の低いOCRでは必須だった「全件目視チェック」や「手修正」がほぼ不要になります。
■ 実例(データ入力事務員を6→1名に削減)
不動産データ(マイソク・デベロッパーから受領する不規則な不動産データ等)の読み取りにおいて、すべてのファイルを画一的にOCR(画像認識)にかけるのではなく、PDF構造化技術を活用したシステム開発の実例を説明します。
重要な前提: 不動産資料(マイソクデータ)の99%はスキャンデータではなくテキストデータで構成されているという前提に基づいています。
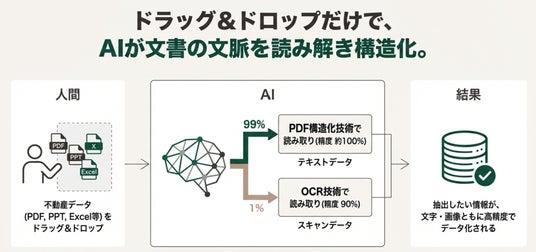
1. ドラッグ&ドロップ(入力と判別)
人間の作業: 不動産データ(マイソク・デベロッパーから受領する不規則な不動産データ等)をドラッグ&ドロップでシステムに投入します。
AIの処理: 投入されたファイルが「テキストデータを保持したファイル形式」なのか、それとも「スキャンデータ(画像)」なのかを瞬時に判断します。
2. 構造化技術による読み取り(全体の99%)
対象: テキストデータを保持しているファイル(全体の99%)。
処理: 画像認識ではなく、データ内部のテキスト構造を直接解析します。
結果: 約100%の精度で読み取りが可能であり、抽出したい情報を文字・画像のまま正確に抽出できます。
3. OCR技術による読み取り(全体の1%)
対象: 紙をスキャンしたような画像データ(全体の1%)。
処理: 従来のOCR技術を用いて読み取ります。
結果: 精度は90%程度であり、10%ほど誤った情報が含まれる可能性があります。
<全体の精度算出>
スキャンデータ(1%)に含まれる微細な読み取りミス(10%)が全体に及ぼす影響は、計算上わずか0.1%(1%×10%)です。 結果として、残り99.9%のデータにおいて正確な読み取りを実現しています。
■ 導入までの流れ
ヒアリング・デモ実施:貴社の課題や対象帳票(PDF)の種類を確認させていただきます。
トライアル検証:実際のデータを用いて、読み取り精度をご体感いただきます。
本導入・運用開始:システム連携や運用フローの構築をサポートいたします。
※詳細はお問い合わせください。
■ Irwin&co株式会社について
Irwin&co株式会社は、「導入するだけのAIではなく、成果を出すAI」を理念に掲げ、生成AIを活用した受託開発を主力事業として展開しています。
社名:Irwin&co株式会社
代表者:代表取締役 アーウィン海
所在地:〒150-0004 東京都渋谷区円山町5丁目5号
設立:2025年6月 社員数:20名(業務委託含む)
事業内容:生成AIに係るシステム開発・コンサルティング・講習会
■ 本件に関するお問い合わせ先
Irwin&co 株式会社
代表取締役:アーウィン海
取締役/広報担当:田中康太郎
E-mail:kotaro.tanaka@irwin-and-co.com
Tel:090-1545-1708
Web:https://www.irwin-and-co.com/