~GENIAC採択企業のVisual Bank、レジャー・娯楽領域の対話音声データで音声・言語系AI開発を支援~

Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、ASR(自動音声認識)、NLP(自然言語処理)、LLMなどの音声・言語系AI開発に向けた「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」の提供を開始しました。
本データセットは、Qlean Datasetが展開する機械学習用データセットラインナップ『AIデータレシピ』に新たに加わるもので、レジャーや趣味、娯楽をテーマに、2名の話者が対話形式で語り合う日本語音声と、その発話内容を書き起こしたトランスクリプトを収録しています。ドラマやアニメなどの作品に対する感想、ゲームやガジェットのレビュー、旅行や外出に関する体験談など、日常的な話題を題材とした会話が含まれます。
収録は台本に依存せず、作品や体験に対する感想や意見交換が自然な流れで交わされる対話を前提としています。こうした構成により、音声認識や対話処理など、実際の会話シーンを想定した音声・言語系AIの研究・開発用途での利用を想定しています。
Qlean Datasetでは、研究用途から商用開発までを見据え、権利処理や利用条件を整理したAI開発用データを提供しています。本データセットもその一環として、日常会話シーンに即した日本語対話データを用いた検証環境の整備を目的に提供されます。
今回提供を開始する「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」の概要
[表1: https://prtimes.jp/data/corp/108024/table/127_1_b4815f81dea030d7c3d316c6eb9e1470.jpg?v=202601150845 ]
「日本語・2話者・レジャーテーマトーク音声コーパスとトランスクリプト」のユースケースイメージ
【研究用途】
- 日本語対話音声認識モデルの検証複数話者が対話する音声を入力としたASRモデルにおいて、話者の切り替わりや応答関係を含む発話の認識精度検証に利用できます。
- 対話文脈を考慮した言語モデル研究話題の展開や相互参照を含む日本語対話テキストを用い、LLMや対話モデルにおける文脈理解や応答生成の挙動を評価する研究に利用できます。
【産業用途】
- 音声UI・対話型AIの検証用途音声アシスタントや対話型インターフェースの開発において、日常会話に近い日本語対話音声を用いた入力処理や対話制御のPoC検証に利用できます。
- 日本語LLMの対話性能評価・追加学習業務会話に限定されない対話テキストを用い、日本語LLMにおける自然な応答生成や対話継続性の評価、ファインチューニング用途に利用できます。
『Qlean Dataset(キュリンデータセット)』について
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する商用利用可能なAI学習用データソリューションです。
画像・動画・音声・3D・テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。
また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援します。
▶ Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
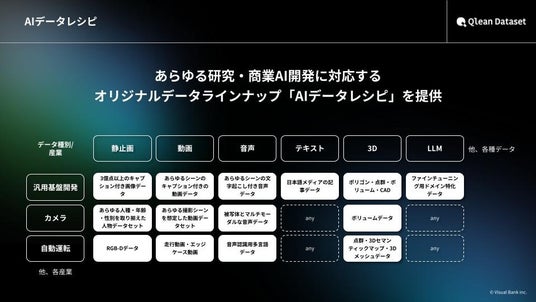


『Qlean Dataset』の提供するデータセット『AIデータレシピ』の特徴
- すべての被写体から同意取得
- 既存データは最短1日で納品可能
- カスタム撮影・収録・収集による独自データ構築にも対応
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL:https://amanaimages.com/about/
【Translation】

Qlean Dataset Launches a Japanese Two-Speaker Conversational Speech Corpus with Transcripts
Natural Japanese Dialogue Data for ASR, Conversational AI, and LLM Development
Visual Bank Inc. (Minato-ku, Tokyo; CEO: Saneyuki Nagai) has announced the release of a new dataset, “Japanese Two-Speaker Leisure-Themed Conversational Speech Corpus with Transcripts,” through its AI training data solution, Qlean Dataset, operated by its subsidiary, Amanai Images Inc.
This dataset is designed for the development of voice and language AI technologies, including ASR (Automatic Speech Recognition), NLP (Natural Language Processing), and large language models (LLMs).
This dataset is a new addition to AI Data Recipe, the machine learning dataset lineup provided by Qlean Dataset.
It consists of Japanese conversational audio recorded between two speakers, paired with corresponding transcripts.
The conversations focus on leisure, hobbies, and entertainment, covering everyday topics such as impressions of TV dramas and anime, reviews of games and gadgets, and personal experiences related to travel and outings.
All recordings were conducted without scripts, allowing participants to exchange opinions and impressions in a natural conversational flow.
By capturing spontaneous dialogue rather than controlled utterances, the dataset is suitable for research and development scenarios that assume real-world conversational settings, including speech recognition and dialogue processing tasks.
Qlean Dataset provides AI development data prepared with clearly defined usage conditions and rights clearance, supporting both research and commercial development.
This dataset is offered as part of that initiative, with the aim of enabling robust evaluation environments based on Japanese conversational data reflecting everyday communication.
Dataset Overview: “Japanese Two-Speaker Leisure-Themed Conversational Speech Corpus with Transcripts”
[表2: https://prtimes.jp/data/corp/108024/table/127_2_b2d909c692a8b53e79d9d73082669b8e.jpg?v=202601150845 ]
Use Case Examples for the “Japanese Two-Speaker Leisure-Themed Conversational Speech Corpus with Transcripts”
Use Case Examples - Research
- Evaluation of Japanese Conversational ASR ModelsThis dataset can be used to evaluate recognition accuracy in ASR models that process multi-speaker dialogue, including speaker switching and turn-taking behavior.
- Context-Aware Language Model ResearchBy leveraging conversational Japanese text that includes topic transitions and cross-references, researchers can analyze context understanding and response generation behavior in LLMs and dialogue models.
Use Case Examples - Industry
- Validation of Voice UI and Conversational AI SystemsFor the development of voice assistants and conversational interfaces, this dataset supports PoC-level validation of speech input processing and dialogue control using natural Japanese conversations.
- Evaluation and Fine-Tuning of Japanese LLMsThe dataset can be applied to evaluate and fine-tune Japanese LLMs for natural response generation and dialogue continuity using conversational text not limited to business-specific scenarios.
About Qlean Dataset
Qlean Dataset is a commercial-use-ready AI training data solution provided by Amana Images Inc., a subsidiary of Visual Bank Inc.
It supports a wide range of data types, including images, videos, audio, 3D assets, and text, enabling both research and commercial AI development in a legally safe environment.
Through collaborations with data partners such as Chiba Lotte Marines Co., Ltd. and Toyo Keizai Inc., Qlean Dataset continues to expand its specialized, industry-focused lineup known as the “AI Data Recipe.”
By reducing the operational burden of data collection and preparation, Qlean Dataset helps organizations establish AI development environments that are both legally compliant and risk-free.
▶ Qlean Dataset: https://qleandataset.visual-bank.co.jp/en
▶ AI Data Recipe: https://qleandataset.visual-bank.co.jp/en/lineup
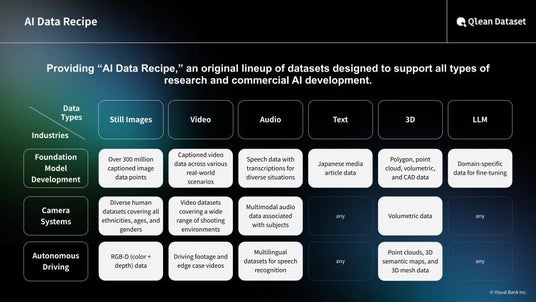


Key Features of Qlean Dataset
- Existing datasets deliverable within one business day
- Custom data collection and recording services available
About Visual Bank Inc.
Visual Bank Inc. is a Tokyo-based startup building Next-Generation Data infrastructure to enhance AI development capabilities under the mission “Unlocking Data Accessibility.”
The company operates THE PEN, an AI-assisted creative tool for manga artists and the Qlean Dataset service.
Its subsidiaries include Amana Images Inc., one of Japan’s largest photostock providers; Qlean Dataset, which leads research and development in AI data; and THE PEN Inc., an AI-assisted creative tool for manga artists.
CEO: Saneyuki Nagai
Address: 6F, C-Cube Minami Aoyama Building, 7-1-7 Minami-Aoyama, Minato-ku, Tokyo
Corporate Site: https://visual-bank.co.jp/en
Amana Images: https://qleandataset.visual-bank.co.jp/en/company-overview